WDCC Preservation Plan and Workflow
version 1.2, 04 June 2024
Preservation Plan
Background
Since 2003, WDCC has been providing long-term preservation of data and metadata for the climate science community, including an optional DataCite DOI data publication. Since then, it has continuously reviewed, evolved, and consolidated the established procedures to ensure that the archived data remain findable and accessible.
Deposition requirements and preservation level
The WDCC has implemented a standardised preservation approach upon all digital assets which it accepts for archival. This means that all archived data have the same preservation level, irrespective of e.g. the size, format or sensitivity of the data. WDCC preserves non-proprietary file formats which are well-established in the climate science community. WDCC strongly recommends the usage of NetCDF or WMO GRIB, both are non-proprietary, open, and international community standard formats. NetCDF is not just a file format but also a set of open software libraries designed for storing, accessing, and sharing scientific data in a backward-compatible manner. The NetCDF libraries provide a platform-independent and self-describing way to store data. In exceptional cases, WDCC also accepts non-preferred file formats, provided they are non-proprietary. It is, however, mandatory that the data objects are additionally provided and archived in an open source format. Before the data are archived in the WDCC, all file formats are checked by the curators as part of the WDCC quality assurance.
Long-term preservation and object re-appraisal
Once data files (netCDF or GRIB) are archived in the WDCC, they are not altered or modified in any way, ensuring the preservation and integrity of the archived data. This also means that the WDCC preserves the data in the formats in which they were originally submitted by the data provider and that there is no format migration.
To ensure long-term preservation, the WDCC has implemented a planned strategy that includes regular backups, data integrity checks and necessary restoration, and the replacement of outdated storage media (see also WDCC Risk Management).
In addition, WDCC actively and continuously manages metadata associated with all archived objects to ensure their long-term accessibility, usability, and integrity. Such metadata comprise the metadata that describe the archived data on the respective WDCC landing page (both human- and machine readable), and in the case of DataCite data publications, the DataCite metadata. By incorporating metadata from the Climate and Forecast (CF) metdata conventions and the CMIP (Coupled Model Intercomparison Project) standard within the data landing pages, WDCC tailors the metadata schema to the specific needs of the climate science community.
WDCC embeds standardized terms (controlled vocabulary) as metadata into the landing page of every archived dataset. The controlled vocabularies comprise CF standard names to describe variables, the CMIP standard to describe specific aspects of CMIP data, and various other external vocabularies to describe, for example, the spatial reference of the data (e.g., GeoNames) or keywords (e.g., Wikidata). The different vocabularies are continuously evolving. For example, the list of CF standard names is continuously being expanded and some CF standard names are being replaced while keeping the old ones as aliases. The WDCC curators are regularly ensuring that the vocabularies embedded in the landing pages are up-to-date. Newly deposited data is always curated according to the latest vocabulary versions.
WDCC also embeds references (related works and data) as metadata within each data landing page. WDCC curators regularly update these references to address broken links and incorporate new research relevant to the data.
WDCC regularly adapts the metadata of DOI data publications to the latest major version releases of the Datacite scheme.
Finally, WDCC curators continuously work on incorporating advancements in data publication into WDCC's data curation workflows, which is often also entailing enhancements in the landing page metadata (as, e.g., the newly implemented PIDs for non-DOI data publication).
| Process | Frequency | Responsible |
|---|---|---|
| Data backup and integrity checks | Daily | WDCC IT |
| Curation of controlled vocabularies of archived data | Biannually | WDCC curators |
| Adaptation to new DataCite metadata scheme | Every major releases | WDCC IT |
| Curation of references information of archived data | Biannually or when informed by data user | WDCC curators |
| Incorporating data publication advancements into WDCC's data curation workflows | Continuously | WDCC curators |
| Review of data submission guidelines | Biannually | WDCC curators |
| Revision of WDCC Preservation Plan | Biennially | WDCC curators |
Removal of assets
In case that a data provider withdraws its data after the publication or in the extremely unlikely event of data damage in the archive that cannot be recovered, the landing page of the data object will still be preserved. However, the WDCC curator will mark the metadata objects as withdrawn or inaccessible.
Preservation Workflow
The WDCC is a data repository which offers long-term archival and publication of datasets relevant to Climate and Earth System Research.
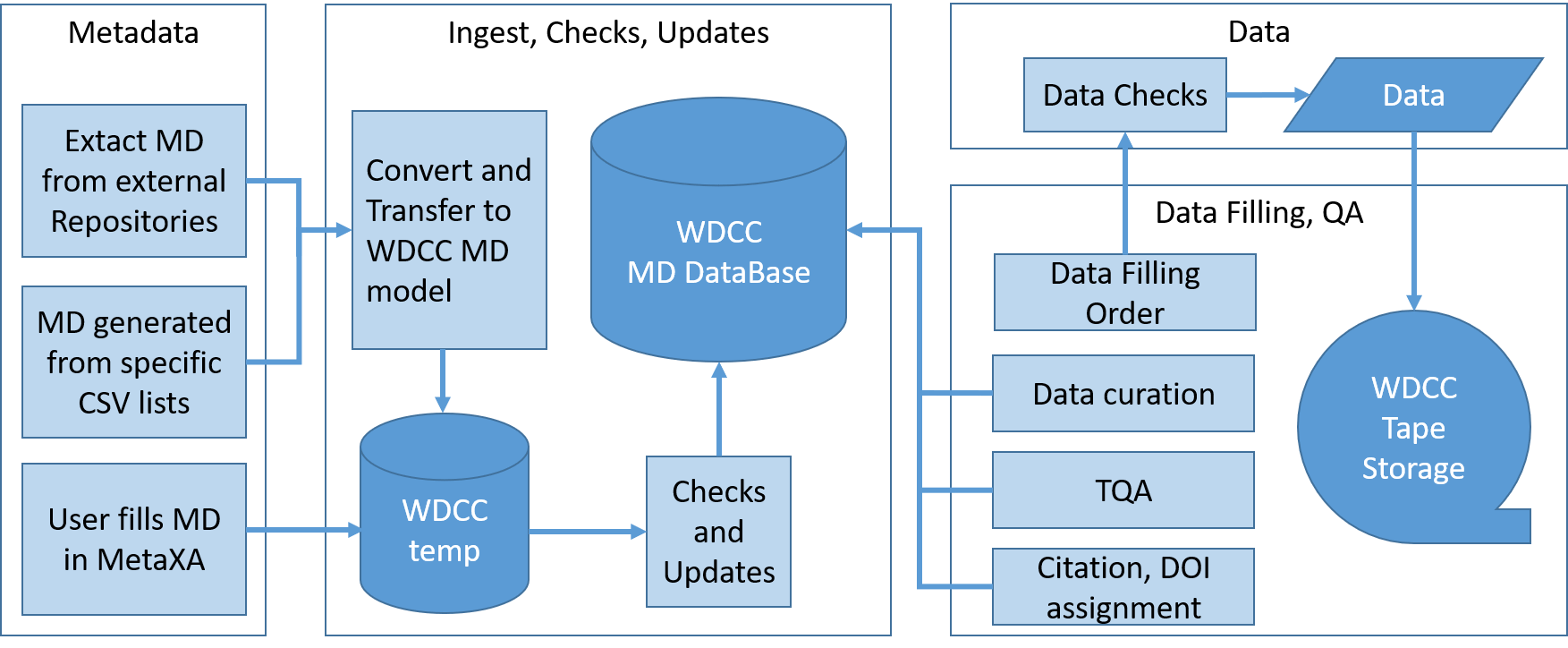
Across the whole preservation workflow, the WDCC follows the guidelines given in the OAIS reference model (Lavoie 2014). The established workflow is described in the figure below and includes four different steps:
- Provisioning of the metadata and data by data provider
- Ingest, checks and updates of metadata to the WDCC Metadata database
- Data checks
- Data filling to tape archive, QA (Quality assurance) of data, linking data with metadata, and curation of data and metadata
The metadata (MD) are provided by the data provider either by the WDCC MD tool MetaXa, a graphical user interface, or by specific CSV files. In collaboration with selected projects, the WDCC curators can extract the MD from external resources (e.g. CMIP6 metadata are retrieved from ESGF).
The MD is stored in a temporary WDCC database (WDCC temp) and checked against the WDCC metadata scheme before it is ingested into the productive WDCC MD database. Hereafter, the data filling process starts. The first step is a data check, including a.o. checksums, format check, and check for zero-byte files. As the second step, data filling is ordered and the data is archived into the WDCC tape archive. In order to ensure that the data has not been altered or corrupted, an automated retrieval of the data back from tape with subsequent fixity checks is implemented. The subsequent technical quality assurance (TQA) is an essential part of the data curation. Curation processes like TQA and DOI assignment generate new MD, added to the WDCC MD database immediately.